Rdfsynopsis
A framework and command-line tool for statistical analyses of RDF datasets.
rdfSynopsis
A framework and command-line tool for statistical analyses of RDF datasets.
The software rdfSynopsis was written in Java. It uses the Apache Jena framework to process RDF data and to query SPARQL endpoints. The goal for the design of RDFSynopsis was to write code that could be used both, as a stand-alone tool operated from the command-line, and as a framework of classes for reuse in other software.
Content
- Approach
- Architecture
- Usage
- Installation (N/A)
- Problems, Known Bugs, Shortcomings (N/A)
- License (N/A)
Approach
During our investigation of structure analysis of RDF datasets, we identified 18 criteria, which help understanding an RDF dataset.
We use two general approaches for the SPARQL-based structural analysis of RDF datasets; first, the Specific Query Approach (SQA), and second, the Triple Stream Approach (TSA).
Specific Query Approach (SQA)
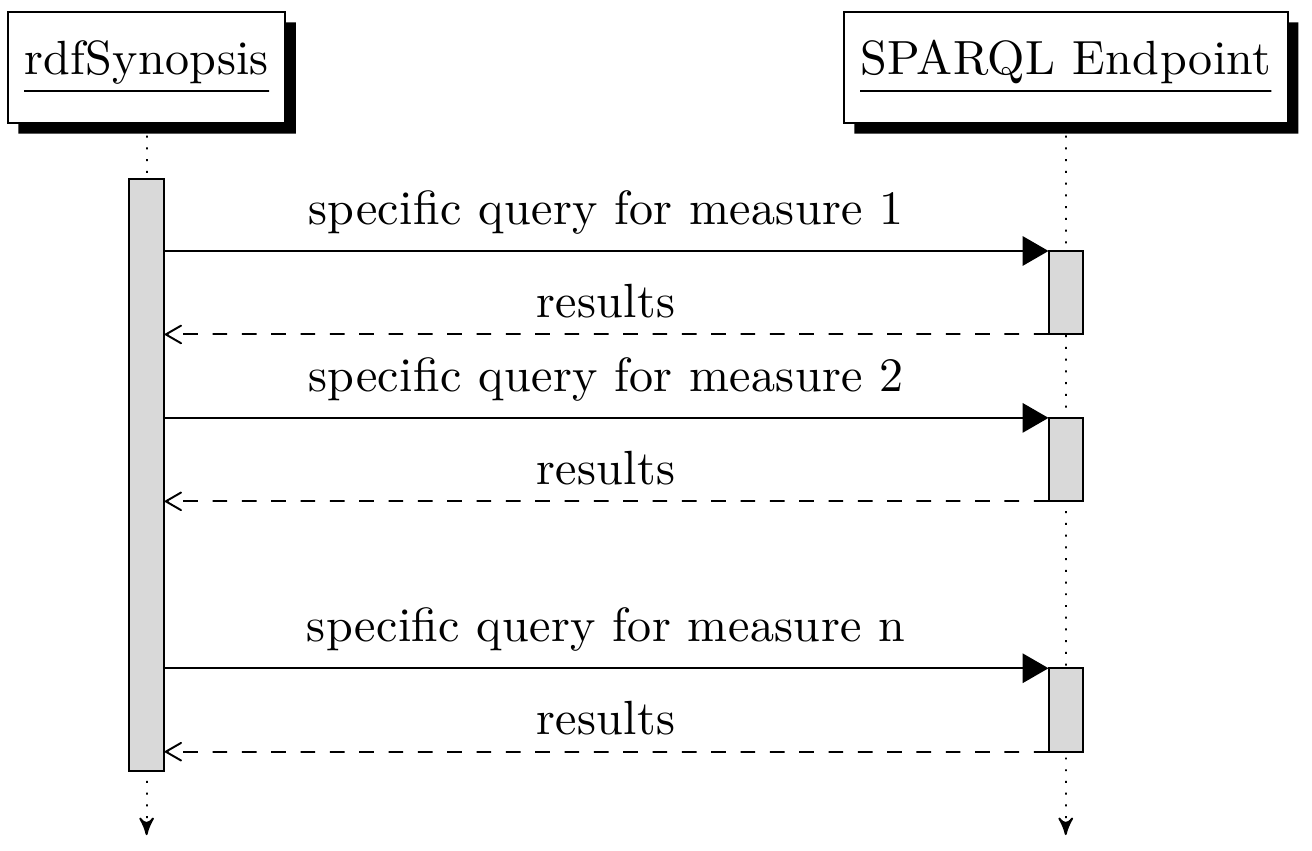
Our first approach to analyze a dataset that is available through a given SPARQL endpoint, is to formulate one SPARQL query per measure. We refer to this as the Specific Query Approach (SQA).
With SQA, we conduct a full analysis of a dataset by subsequently performing a set of queries, each of which is specifically tailored to one measure. This simple process is visualized in the sequence diagram.
Triple Stream Approach (TSA)
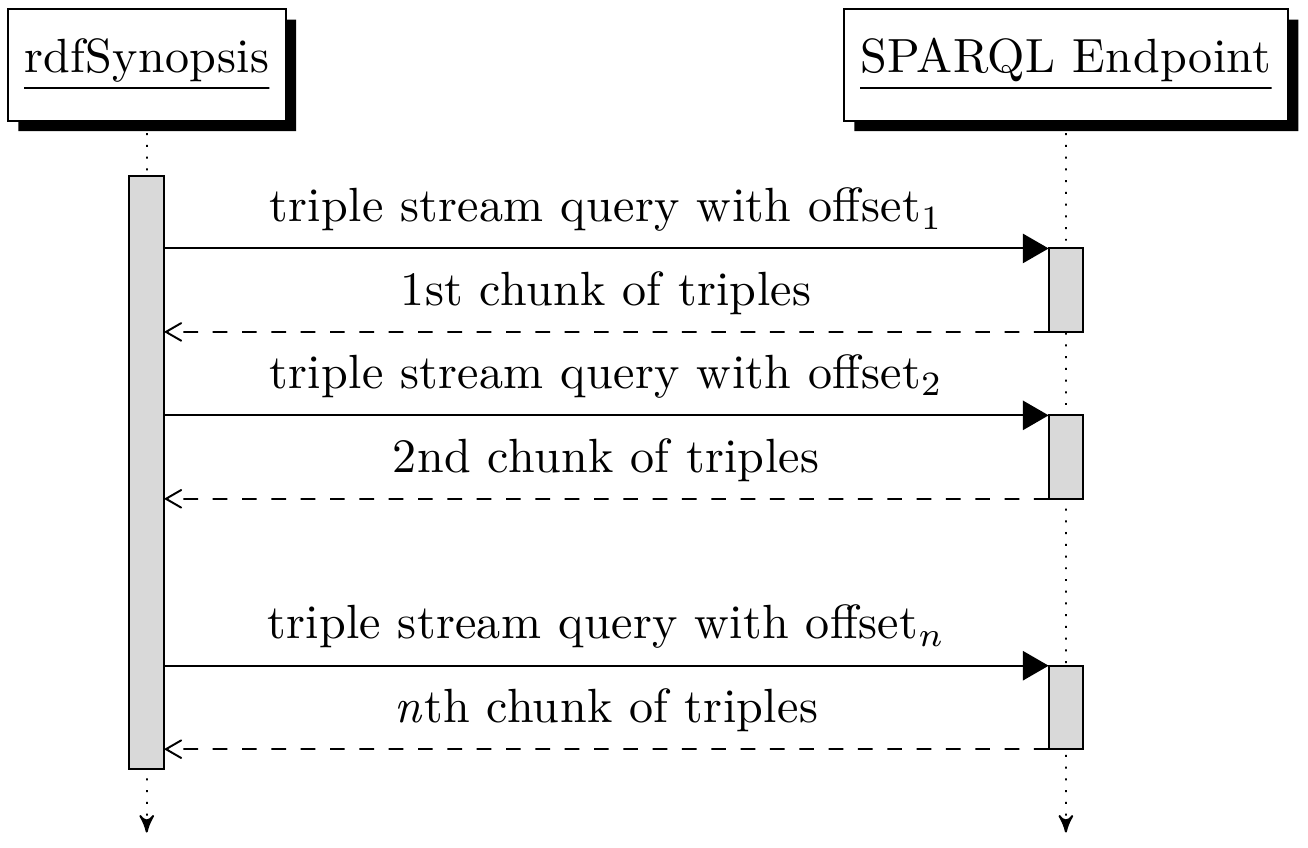
Our second approach for a SPARQL-based dataset analysis, is to retrieve and analyze a sequence of triples. We refer to this as the Triple Stream Approach (TSA). With TSA, we conduct a full analysis of a dataset by subsequently retrieving all triples of a dataset. The different measures are implemented in terms of triple filters; each measure decides whether and how it takes a triple into account. The analysis is finished when all triples of a dataset have been filtered by each measure.
In the majority of cases it will be infeasible to retrieve the full dataset with one query. Triple stores usually constrain memory and time used per query, and these constraints are easily exceeded for larger datasets. We therefore perform several queries each retrieving only a part of the full dataset. This process is visualized in the sequence diagram.
The following SPARQL query can be used to subsequently retrieve all triples of a dataset.
SELECT ?s ?p ?o
WHERE {?s ?p ?o.}
ORDER BY ...
LIMIT ...
OFFSET ...
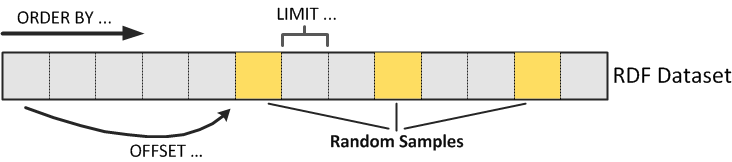
The graph pattern {?s ?p ?o.} matches all triples (line 2). We use the LIMIT keyword to define the “chunk size”, i.e., an upper bound on the number of received triples (line 4). The ORDER BY clause is used to define a sequential order on the otherwise unordered RDF graph (line 3). We iterate over this sequence by subsequently using offsets incremented by the “chunk size” (line 5). The figure below illustrates how the different SPARQL keywords define a sequence of triple “chunks”, that can be iteratively requested, to create the triple stream.

Partial Analysis & Random Sampling
An obvious disadvantage of the plain Triple Stream Approach is that it requires the transfer of the whole dataset from the SPARQL endpoint; a very expensive and time-consuming process. A potential solution to this problem is to refrain from a full analysis and only request a subset of all triples. Because the ORDER BY clause imposes some sequence on the triples in the dataset, a partial analysis, that only takes the first k triples into consideration, is very unlikely to produce results that are representative for the full dataset. In order to mitigate this adverse effect and to obtain a more representative sample of triples, we follow an approach to randomly select the parts we request from a dataset. This approach is visualized in the figure below.
Architecture
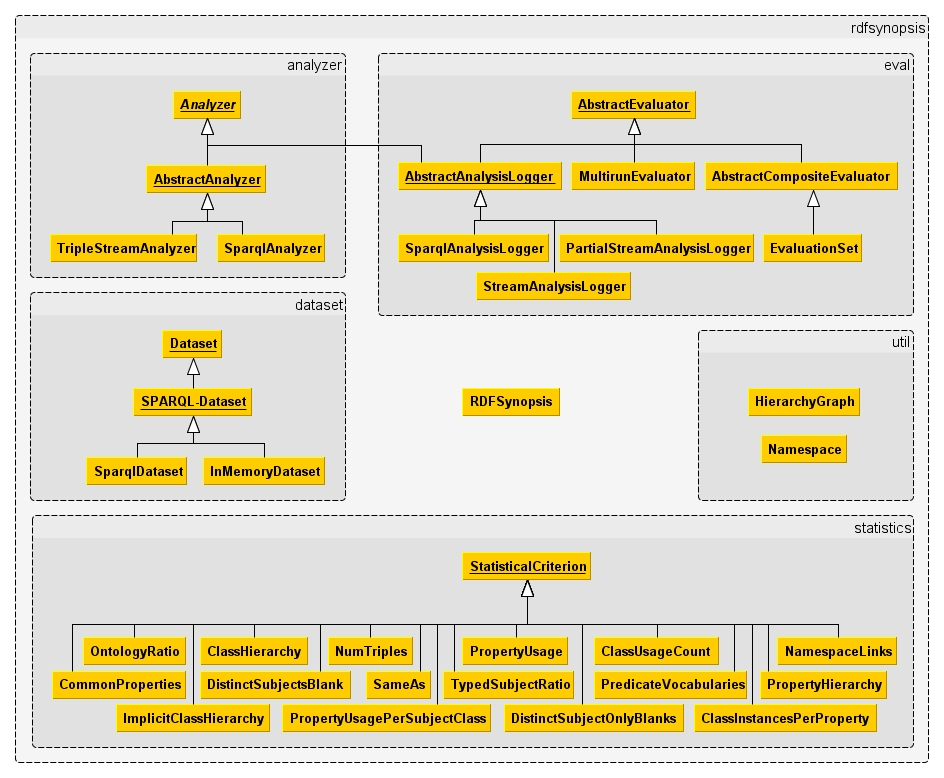
The figure below presents the class hierarchy and package arrangement. Three concepts are at the center of RDFSynopsis’s design: Datasets, Statistical Criteria, and Analyzers. The basic idea behind these concepts is to define a dataset analysis in three steps.
- Define the dataset that shall be analyzed.
- Define the statistical criteria according to which the dataset shall be analyzed.
- Provide the dataset and the criteria to an analyzer, and let it do the work.
Datasets
A dataset represents any collection of RDF data. Our class SparqlDataset represents datasets that can be queried with SPARQL queries. The class offers a single method query that can be used to pose SPARQL queries against the dataset. Throughout the code, we only use this method for data access. The subclasses SparqlEndpointDataset and InMemoryDataset encapsulate access to remote datasets which are identified via an endpoint URI, and local datasets which are loaded into memory, respectively.
public abstract class SparqlDataset extends Dataset {
public abstract QueryExecution query(Query query);
}
Statistical Criteria
A statistical criterion represents a single analytic measure. The abstract class StatisticalCriterion provides three public methods. The first, flushLog, prints the current state of measurements. The second, considerTriple, represents the filterTriple(s, p, o) function, implementing the Triple Stream Approach . The third public method is processSparqlDataset which implements the Specific Query Approach. It uses the query method of the provided SparqlDataset, and delegates parsing of query results to its concrete subclasses. The specific SPARQL queries for each criterion are loaded from separate .sparql-files. This process is implemented in StatisticalCriterion, but has been omitted for brevity.
public abstract class StatisticalCriterion {
// print current measurements
public abstract void flushLog(PrintStream ps);
// filter triple (TSA)
public abstract
void considerTriple(Resource s, Property p, RDFNode o);
// process query results (SQA)
abstract void processQueryResults(ResultSet res);
// query dataset (SQA)
public void processSparqlDataset(SparqlDataset ds) {
...
// execute query and obtain results
QueryExecution qe = ds.query(query);
ResultSet results = qe.execSelect();
// delegate result processing to subclass
processQueryResults(results);
...
}
}
Analyzer
An analyzer represents a single analysis configuration. The AbstractAnalyzer class defines four public methods. The first two, addCriterion and setDs, are used to configure the analysis with regard to dataset and criteria. The third method, performAnalysis, actually performs the analysis and prints the results to the provided PrintStream. The fourth method is equals. AbstractAnalyzer and all subclasses of StatisticalCriterion re-implement this standard method, making analysis results comparable by calling analyzer1.equals(analyzer2). The performAnalysis method is implemented differently for SQA and TSA. The subclass SparqlAnalyzer (SQA) calls processSparqlDataset for each criterion, while TripleStreamAnalyzer (TSA) creates a triple stream and calls considerTriple for each criterion and triple. The triple stream is created by subsequently querying the dataset with increasing OFFSET parameters. Random Sampling is implemented by calling Collections.shuffle(offsets) on a precomputed list of offsets.
public abstract class AbstractAnalyzer implements Analyzer {
// define criteria
public Analyzer addCriterion(StatisticalCriterion sc) { ... }
// define dataset
public Analyzer setDs(SparqlDataset ds) { ... }
// perform analysis and output results
public abstract void performAnalysis(PrintStream ps);
// compare analysis results
@Override
public boolean equals(Object obj) { ... }
}
The classes in the eval package have been implemented for the evaluation of our work, and do not represent core components of rdfSynopsis. Hence, they are not further discussed.
Usage
Framework Usage
The following examples demonstrate the use of RDFSynopsis’s classes. We analyze the number of triples of a SPARQL endpoint using TSA (Example 1), and find the common properties of an in-memory dataset using SQA (Example 2).
Example 1
TripleStreamAnalyzer tsa = new TripleStreamAnalyzer()
.addCriterion(new NumTriples())
.setDs(new SparqlEndpointDataset("http://..."))
.setRandomSampling(true)
.setTripleLimit(500);
tsa.performAnalysis();
Example 2
SparqlAnalyzer sqa = new SparqlAnalyzer()
.addCriterion(new CommonProperties())
.setDs(new InMemoryDataset("file:../data/peel.rdf"));
sqa.performAnalysis();
Command-Line Usage
RDFSynopsis also provides a command-line interface.
> java -jar rdfSynopsis.jar --help
Usage: rdfSynopsis [options]
Options:
-all, --allCriteria
Use all available criteria for analysis.
Default: false
-c, --criteria
A space-separated list of criteria to use for analysis,
e.g, "-c 3 5 7"
-ep, --endpoint
The SPARQL endpoint URL that shall be analyzed.
-f, --file
The RDF dataset file that shall be analyzed.
-h, --help
Print this usage information.
Default: false
-lc, --listCriteria
Print list of analytical criteria.
Default: false
-mnq, --maximumNumberQueries
The maximum number of queries to perform a partial
analysis; "-1" means "infinite". (TSA only, NA)
Default: -1
-ob, --orderBy
One of the following variables used to define an order in
the triple stream: subject, predicate, object (TSA only)
Default: subject
-o, --outFile
The filename used to store analysis results. (NA)
-rand, --randomSampling
Use a "random sampled" triple stream. (TSA only)
Default: true
-rf, --resultFormat
One of the following result output formats: text,... (NA)
Default: text
-sqa, --specificQuery
Use one specific SPARQL query per criterion. (SQA)
Default: false
-tl, --tripleLimit
The maximum number of triples requested per query.
(TSA only)
Default: 50000
-tsa, --tripleStream
Use generic SPARQL queries to create a triple stream. (TSA)
Default: false
> java -jar rdfSynopsis.jar --listCriteria
[id] criterion
------------------------------------------
[1] class usage count
[2] triples per subject class
[3] explicit class hierarchy
[4] implicit class hierarchy
[5] ontology-ratio
[6] typed-subject-ratio
[7] property usage
[8] predicate vocabularies
[9] property usage per subject class
[10] class instances per property
[11] explicit property hierarchy
[12] implicit property hierarchy
[13] distinct blank subjects
[14] namespace links
[15] distinct subject-only blanks
[16] triples
[17] sameAs
[18] common properties
The above examples can be invoked from the command-line. The -c parameter is used followed by a list of numbers to define the desired criteria; -lc prints the number-to-criteria mapping.
Example 1
> java -jar rdfSynopsis.jar -tsa -rand -tl 500 -c 16 -ep http...
Example 2
> java -jar rdfSynopsis.jar -sqa -c 18 -f ../data/peel.rdf